Outrunning a Hurricane
Two guys are walking thru the woods when they see a charging Grizzly Bear. First guy says "Run for it!" Second guy says, "You can't outrun a Grizzly!" First guy says "I don't have to outrun the bear, I just have to outrun YOU."
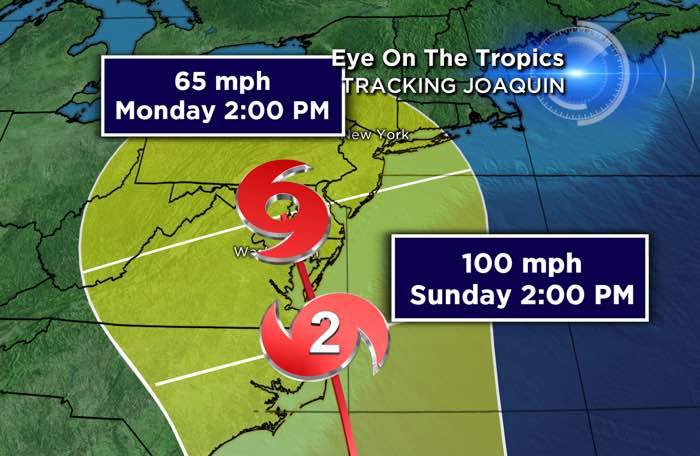 This past Fall, Hurricane Joaquin was threatening to hit the East Coast. Many models had Northern Va (also known as US East-1) in its crosshairs. The Derecho of 2012 showed that AWS Regions are vulnerable to weather related events. The derecho knocked out big names like Netflix, Instagram and Pinterest for up to three days. It was our first look at who the big players that were using AWS.
This past Fall, Hurricane Joaquin was threatening to hit the East Coast. Many models had Northern Va (also known as US East-1) in its crosshairs. The Derecho of 2012 showed that AWS Regions are vulnerable to weather related events. The derecho knocked out big names like Netflix, Instagram and Pinterest for up to three days. It was our first look at who the big players that were using AWS.
3 years later, there are a LOT more large companies in the cloud. When an event like this happens again, and unfortunately it will, there will be a mad scramble for resources in other AWS Regions. A 2013 report by Netcraft showed that 60% of all web facing instances were in the US East Region. There are not enough instances in both US West Regions to absorb the inevitable load that would come.
We made the call on Wednesday night, 5 days prior to the arrival of Joaquin, to put on our running shoes. We weren't interested in outrunning Joaquin, but to outrun the rest of you. If you are running in a data center there was nothing you could do other than to dust off that DR binder, start sandbagging and print your resume before the power goes out.
With a team of 6, we had the frontend site and a functioning backend system up and running in 8 hours. By Friday afternoon, we had 90% of our systems running in two regions. You read that right. In less than 2 days, with no one working overtime, we had fully migrated CustomInk across the United States. The other 10% were Tier 2 applications that could afford a 3-5 day outage and not critical to the business.
This was our true test of the cloud's abilities but it also reinforced the groundwork laid down by my team years earlier. CustomInk is truly a DevOps organization. We have fully embraced Infrastructure as a Service in WebOps and everyone has bought into our cloud environment. We have daily standups, blameless postmortems and the team shares the workload and on-call. No one is siloed as the infrastructure guy or supports a single company org. One for all...!
In regards to our infrastructure, Infrastructure as Code is a working principle of the WebOps team. IaC is a great buzzword and many of my peers claim this. If you can't build your applications in less than 5 Chef/Ansible/Puppet commands please move aside. This single principle allowed us to deploy 90 applications across 200 load balanced servers in two availability zones in a new AWS Region. Our engineers are able to literally fire off the commands to build out an application and then move on to the next application. Rather than futzing with servers, we could focus on database replication, networking and security groups.
The conclusion was a bit anti-climatic. There were a few high fives and congrats by senior management. The systems ran over the weekend and we scaled them back on Monday. Our applications are now multi-region and and we treat US West-2A as a 4th AZ. At the end of the day, we proved that our cloud infrastructure was elastic and dynamic and our WebOps Team was agile and able to respond to what we believe is our biggest threat.
