Keeping Customink.com Fast and Reliable with AWS CloudFront and Application Load Balancer
In early 2020, Custom Ink implemented an AWS Application Load Balancer in front of CustomInk.com and decommissioned a set of EC2 instances running an open-source HTTP accelerator called Varnish. This transition was the latest step in our long journey to make CustomInk.com faster, more reliable, and easier to maintain. Read on to see how we used caching and load balancing to make our website more scalable and less complicated, and how we eventually got to use Amazon Web Services' managed applications to solve the problem without having to manage more servers.
The Objective: Keeping Customink.com Fast and Reliable
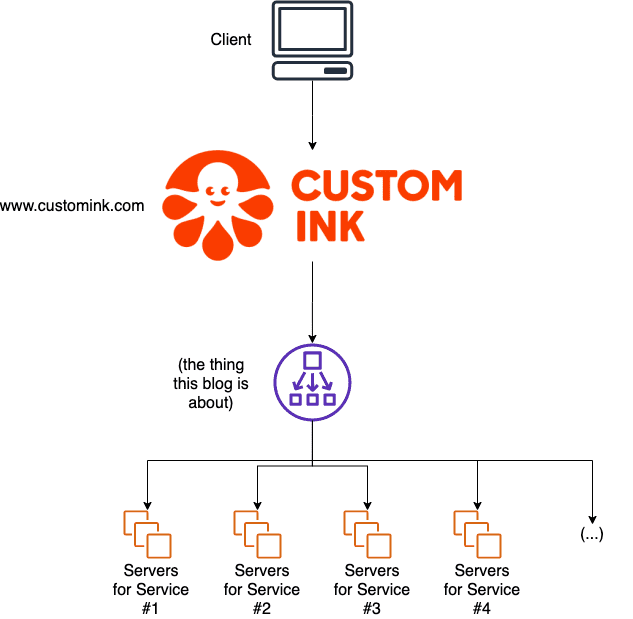
Although designing a t-shirt or creating a fundraiser feels like a cohesive experience, CustomInk.com is actually made up of many different applications that service different features of the website. For instance, if you log into the website to view your cart, you are authenticating with a service that's just for keeping track of your account. Then, when you go to create a group order form to ship a cool shirt to the rest of your team, you're actually talking to an application whose only job is to manage group orders.
We spread these functions out across many different services so it's easier to scale one or the other to adjust to demand without having to allocate a lot of resources we don't need to use. (During a busy time with lots of folks logging in, the account management service might be doing a lot of work, while "Ink of the Week" might not.) It's also a great way to limit the impact of changes, and prevent a problem in one part of the website from bringing everything else down.
These services all serve two kinds of content: dynamic content (like price and shipping estimates, how your fundraiser is doing, and renders of your new shirt design), and static content (fonts, images, video files, and stylesheets). We need a server to serve dynamic content; after all, it needs to run code and crunch numbers to decide what to show you. However, we don't necessarily need the server to send you static content; since it's not going to change based on what you ask the server, we can use a cache to store that content on yet another server. That way, the servers running "Fundraising" can focus entirely on thinking about launching your new fundraising campaign and figuring out how much money it's making, instead of showing you the same picture of a shirt that it's probably already sent a thousand times already. That part can be handled by the cache.
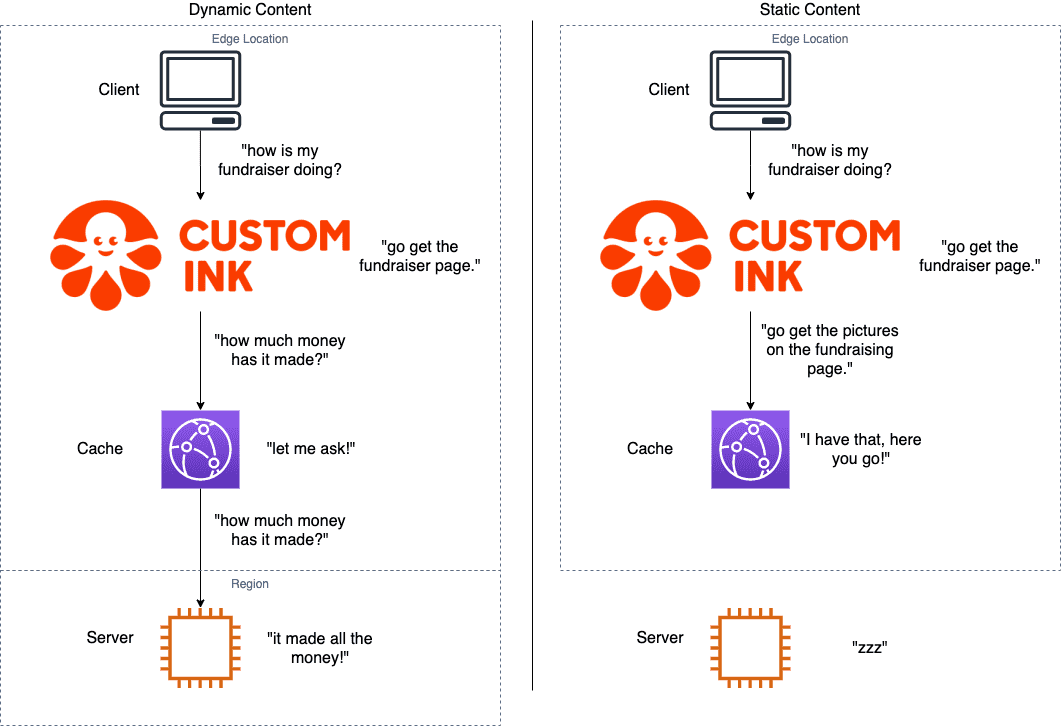
This is a great way to run a modern, scalable website, but it creates a challenge: how do we direct all that traffic going to "CustomInk.com" to all of those servers, and how can we store static content like images somewhere closer to you to reduce the load on those servers?
Original Approach: Varnish
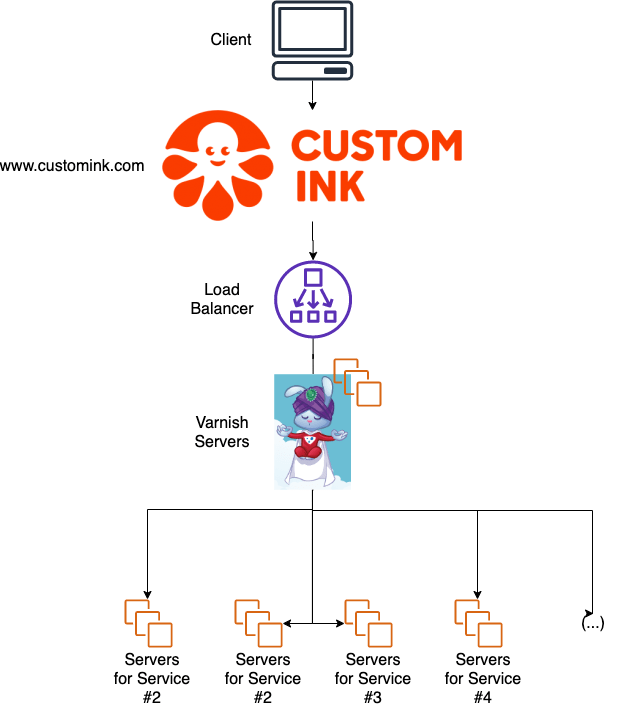
The first way Custom Ink approached this problem was by using an open-source tool called Varnish. This software can, among other things, do path routing (so requests to a certain part of the website, like www.customink.com/fundraising, go to the "Fundraising" servers) and cache static content (so you can see images without having to hit the "Fundraising" server every time). We originally ran Varnish on a dedicated set of servers in a datacenter, and later as EC2 instances in Amazon Web Services. When you navigated to www.customink.com in your browser, your request would hit Varnish first before it made it to any of the application servers.
This worked pretty well. From the user's perspective, they were using CustomInk.com; not "Fundraising", "Profiles", or "Groups". It even let us balance load between multiple servers providing an application, so if one went down, it would send your request to the ones that were still up. It also took up a lot of the heavy lifting serving static content. Would you believe that the font that Custom Ink uses for some logos, icons, and shapes was served up 5,628,019 times in April of 2020? That's a lot of scroll arrows; 46.16 GB worth, to be exact. There's no reason an application server should have to deal with that, and happily, the cache did that instead.
Varnish also stores this content in memory - so when you loaded a website, it didn't even need to check the disk to go get those images and icons ready for you. As soon as you go to the site, images, fonts, and stylesheets are all queued up for you. This makes the website load faster, since the static content can reach you faster and the backend servers can focus on serving up your dynamic content instead of sending you pictures of Inky.
Friction: Managing Infrastructure
Using Varnish solved a lot of problems, but created some new ones. As mentioned above, Varnish ran on servers. This meant we needed to patch them when they needed updating, monitor them so we knew when they were running low on resources, and put them behind a load balancer so other servers could take up the load if one failed. Also, because all incoming traffic to the website was hitting Varnish, we needed to be able to scale those servers horizontally to handle the load - and we had to do it very fast and very well, since if Varnish had problems, the whole site had problems. (No pressure.)
Varnish is a very flexible, very powerful tool that lets you do a lot of different things in a lot of different ways. Not only does it route traffic to backends, but it opens up a lot of very complex tuning settings that matter a lot when you're taking care of your own load balancer on your own servers. The majority of these settings make very little sense to an engineer who hasn't spent months operating Varnish, and we very rarely changed them. Varnish Configuration Language (or VCL) can get very complex very fast; in fact, we wound up writing a little DSL on top of it using the Chef cookbook we used to spin up more Varnish servers, just so it was simpler for an engineer to add a new server to a backend group.
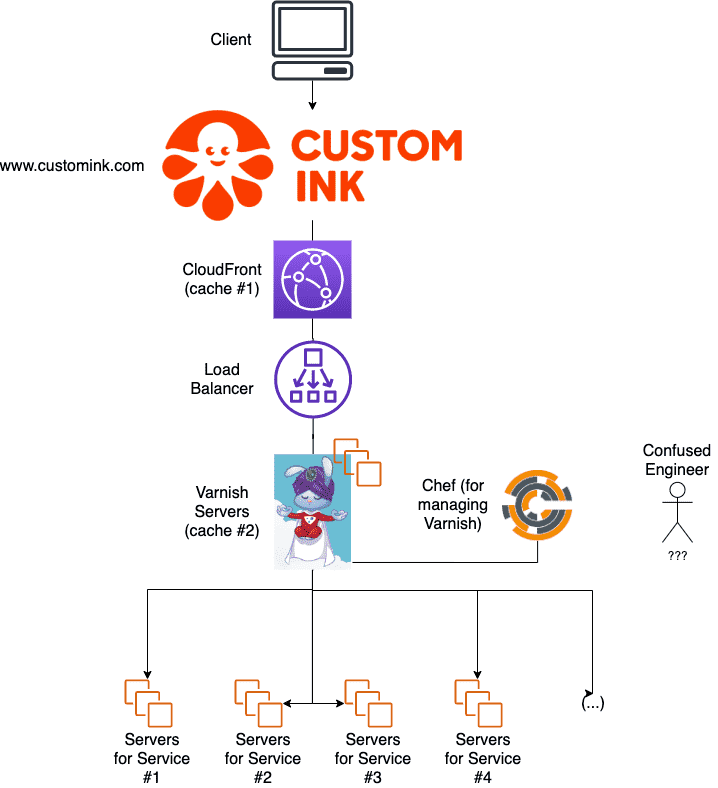
While this worked, it was more risky than we would have liked. The one service that could take the whole site down was held together by a configuration language few of us knew, and our Chef cookbooks - while they did what we needed - could only add more Varnish servers and more backends. If we had needed to jump in and start really tuning Varnish, we would not have been able to move quickly.
Just to make things more complicated, a few years later, we also started using AWS CloudFront. I'll go into more detail on that in the next section, but for now, suffice it to say that we had two caches as a result of that - Varnish, and then CloudFront. That meant that there was a delay between when a resource was updated, when it was reflected in the first cache, then the second cache. This made it hard to diagnose problems.
New Approach: AWS Native Services
Today, the vast majority of Custom Ink's services are hosted on Amazon Web Services. They take many forms, varying from serverless Lambda functions to traditional EC2 instances. We try to use cloud-native, AWS-managed services wherever we can; after all, if those services break, it's AWS that will go fix them, not us. It's easy to manage and deploy these services with CloudFormation and Terraform, so it's easy for us to keep configuration in code and tweak them when we need to. AWS has a very big mindshare and community (that is, it's easier to google when we have problems), and their support is also very responsive and informed. As a result, the more we can offload to Amazon, and the less servers we have to look after, the better. This has meant adopting Route53, Elastic Load Balancers, S3, Lambda, API Gateway, Elastic Kubernetes Service, and more over the years.
Eventually, as the difficulty of maintaining our Varnish implementation became obvious, we started to look for a way to replace it with services provided by AWS.
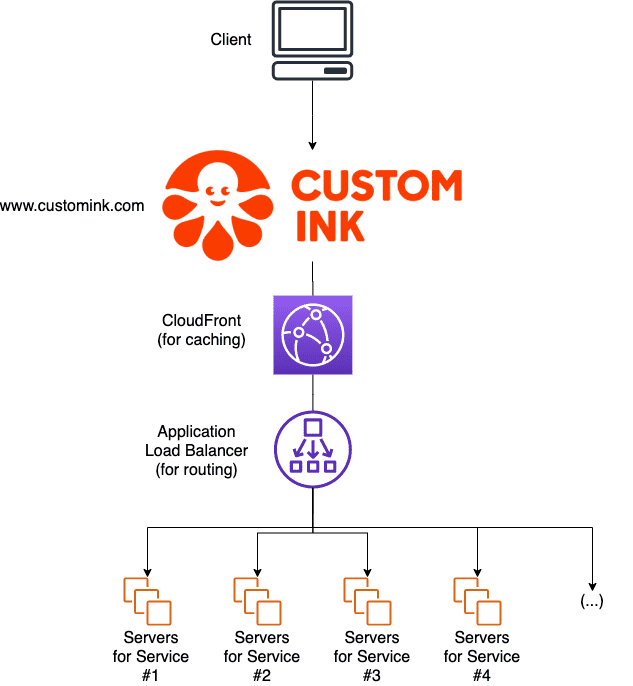
Application Load Balancer
AWS' Application Load Balancer is a high-availability managed layer-7 (HTTP) load balancer meant to route requests to specific paths across groups of servers. We arrange groups of servers into resources called Target Groups; for instance, all of the "Fundraising" servers go into the "Fundraising" Target Group, and then we create a Listener Rule that instructs the ALB to send all traffic going to "www.customink.com/fundraising" to that Target Group. Both the load balancer and target groups can span multiple Amazon availability zones, giving us high availability if a datacenter were to fail.
This allows us to totally replace the path routing functionality provided by Varnish. Because it's a managed service, Amazon is responsible for their scaling and availability (not us); we just provision an ALB, point it at some servers, and relax. Configuration is easy; we can either point-and-click, or write it all up in a CloudFormation or Terraform template using the same syntax we use to manage all of our other AWS infrastructure.
CloudFront
AWS' CloudFront is a high-availability managed CDN meant to serve static files from edge locations around the world. We set up a CloudFront distribution and set up backends called Origins; the sources of static content, be they S3 buckets with images or the load balancers in front of our services. CloudFront caches static content after the first time it's called - and an added benefit of CloudFront is that instead of caching it on EC2 instances in the regional data centers (like Varnish did), it caches them at edge locations, which are often much closer to users than the data centers our EC2 instances are in. Requests that don't hit a cached item are routed to the Origin, which serves up the response. As an added bonus, CloudFront also handles HTTPS offloading for us.
CloudFront let us replace the caching functionality in Varnish, and improves on it by caching at edge locations instead of on servers. Like the ALB, it is totally managed by Amazon; all we have to do is tell CloudFront what to cache, have it point the rest of the traffic at the origin, and relax. No monitoring, managing threads, or adding more memory. (We actually added CloudFront well before we removed Varnish, which led to the double-cache issues alluded to earlier).
Transition: Strangler Pattern
![]()
Given the critical role Varnish played for our website, we knew we needed to implement this change cautiously; we didn't want to make the change and suddenly break some paths or make the cache hit ratio worse. The WebOps team would need to work closely with all of the fire teams that worked on these individual services, and make sure that we were able to test their performance and cache-hit ratios before and after we switched away from Varnish.
Asking all of the developers in Technology to drop what they were doing and help facilitate that would've been unnecessarily disruptive (not to mention a little rude). Happily, we didn't need to do that; we had the option of making the transition one service at a time, so we could change one service in staging, work with a handful of developers to test it out, and make the change in production a few days later. This way we could slowly slice services out of Varnish and into the ALB one by one, without juggling a massive testing effort filled with inter-dependencies and fraught with risk.
The first step we took was to introduce an Application Load Balancer between CloudFront and Varnish. The ALB didn't change anything functionally; it only had one listener rule, which just sent all traffic to a target group with the Varnish servers in it. Varnish handled the rest of the routing. With this done, we were done touching CloudFront - we just changed its default origin to be this new ALB instead of the Classic ELB that used to serve up the Varnish servers.
This ALB was where we would gradually add new listener rules, grabbing traffic headed for "Fundraising" and sending it right to the Fundraising servers, bypassing Varnish. Over time, we would see requests to Varnish go down until eventually every service was being handled by the ALB. At that point, we knew we could terminate the Varnish servers. This was a fairly relaxed effort; we added about two services to the ALB a week, giving ourselves plenty of time to check functionality and cache-hit ratio between when we made the switch in staging and when we did it in production.
To test cache performance, we turned on access logs for the Application Load Balancer, and turned on logs for CloudFront as well. (Both went straight to S3, which is the best way to store massive files.) We used Athena to query those logs after each application cutover to verify that the cache-hit ratio had not degraded, and that the ALB was routing requests to the right target group. It's hard to overstate how helpful S3 and Athena were here, since these logs represented every HTTP request hitting customink.com - they were huge, and it would've been expensive and slow to do something like this on another service.
What Did We Gain?
After the last service cutover, we saw zero traffic hitting the Varnish target group; every request was being funelled by the ALB to the right servers, and meanwhile, the cache-hit ratio stayed largely the same. We were able to terminate the Varnish servers, saving ourselves a sizable amount of EC2 spend.
We were also able to immediately scrap the Chef cookbook that had been used for managing Varnish, which amounted to hundreds of lines of Chef code and template files. This made it much easier to ramp up new engineers; it's much easier to learn the AWS ALB than Varnish's VLC (or the Chef cookbook we put on top of it). Adding and removing servers got less scary, and keeping track of infrastructure as code got much simpler. We currently configure the ALB using a CloudFormation template which lives in Git; adding or removing a server or path is as easy as opening a PR.
Finally, monitoring got much easier; requests and responses to each target group in the ALB is exposed as a CloudWatch metric, which makes it easy to create dashboards and check for things like increased 5xx errors and other anomalies. As I mentioned earlier, we also got ALB logs streaming to S3, allowing for (relatively) cheap and easy traffic analysis.
Overall, the move away from Varnish and to Amazon-managed services made it easier for us to keep CustomInk.com quick and reliable by reducing the amount of overhead involved in caching and routing traffic to multiple backend servers. Coming out of this, we have less servers to manage, managing incoming traffic is easier, and more of the heavy lifting is managed by AWS, not us.
